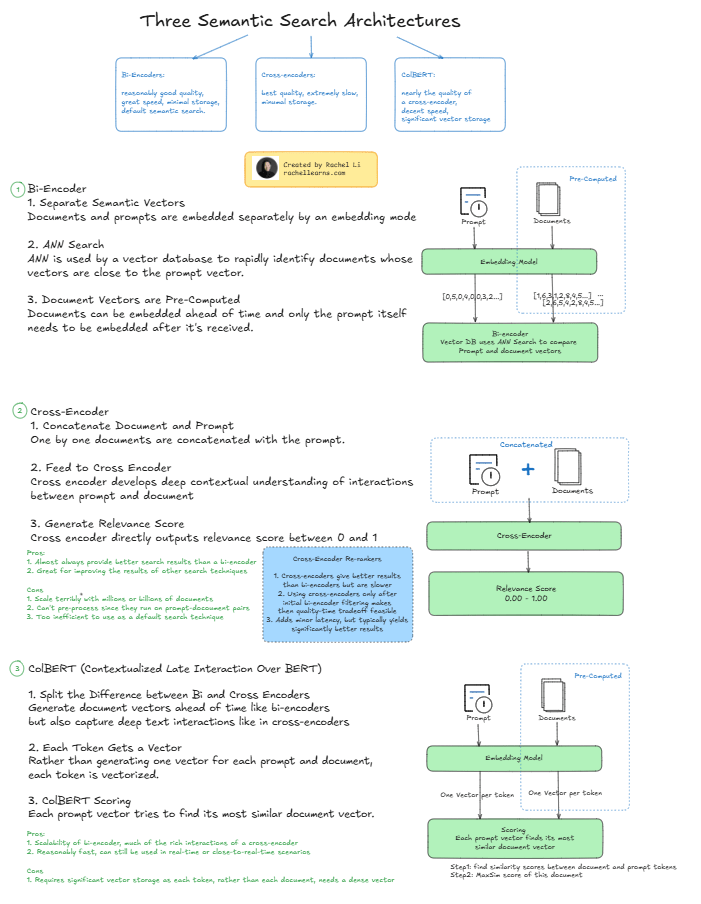
If you’re building or improving semantic search systems, understanding the three primary architectures—Bi-Encoder, Cross-Encoder, and ColBERT—is crucial. Each has trade-offs in quality, latency, storage, and use cases. Here’s a quick comparison:
1️⃣ Bi-Encoder
✅ Fast and scalable
✅ Great for production
✅ Pre-computed document vectors
🔻 Moderate quality compared to others
2️⃣ Cross-Encoder
✅ Best quality—contextual understanding of prompt + document
🔻 Extremely slow
🔻 Not scalable for large corpora
🔻 Typically used for re-ranking top results, not full corpus search
3️⃣ ColBERT (Contextualized Late Interaction Over BERT)
✅ Combines speed of Bi-Encoders with depth of Cross-Encoders
✅ Token-level interaction
✅ Ideal for medium-quality search at reasonable performance
🔻 Requires more vector storage (per token vs. per document)
📌 TL;DR:
- Need speed & scale? Use Bi-Encoders
- Need top precision? Use Cross-Encoders for re-ranking
- Need a balance? Try ColBERT
Which one are you using—or excited to try? 🚀
#AI #SemanticSearch #LLM #Embedding #VectorSearch #NLP #RAG #ColBERT #CrossEncoder #BiEncoder

Leave a comment