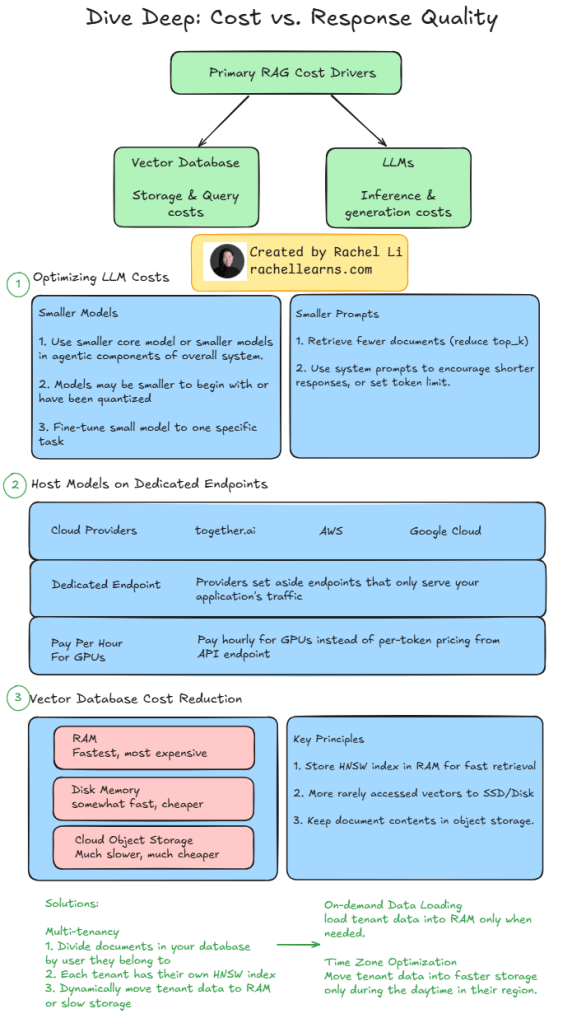
Whether you’re optimizing inference pipelines or managing retrieval architecture, balancing cost and response quality is key to running a scalable production system.
💸 In this visual, I break down the primary cost drivers in Retrieval-Augmented Generation (RAG) systems:
- LLMs – inference & generation costs
- Vector databases – storage & query costs
Here are a few strategies that have worked in practice:
✅ Use smaller or quantized models, especially in agentic workflows
✅ Reduce top_k or use system prompts to constrain output length
✅ Host models on dedicated GPU endpoints to avoid per-token API charges
✅ Tier your vector storage: RAM > SSD > cloud object store
✅ Dynamically load HNSW indices only when needed
✅ Optimize for time zone–based access patterns
If you’re building or scaling a RAG system, these cost levers can make a big difference.
💡 Curious how others are reducing RAG costs in production? Let’s compare notes. 👇
#AI #LLM #RAG #MLOps #RetrievalAugmentedGeneration #VectorSearch #CostOptimization #LangChain #OpenAI #GenAI #rachellearnsAI

Leave a comment