Deploying Retrieval-Augmented Generation (RAG) in the real world isn’t just about getting the model to work — it’s about making it work at scale, under pressure, and with messy data.
Here are some of the toughest challenges I’ve encountered 👇
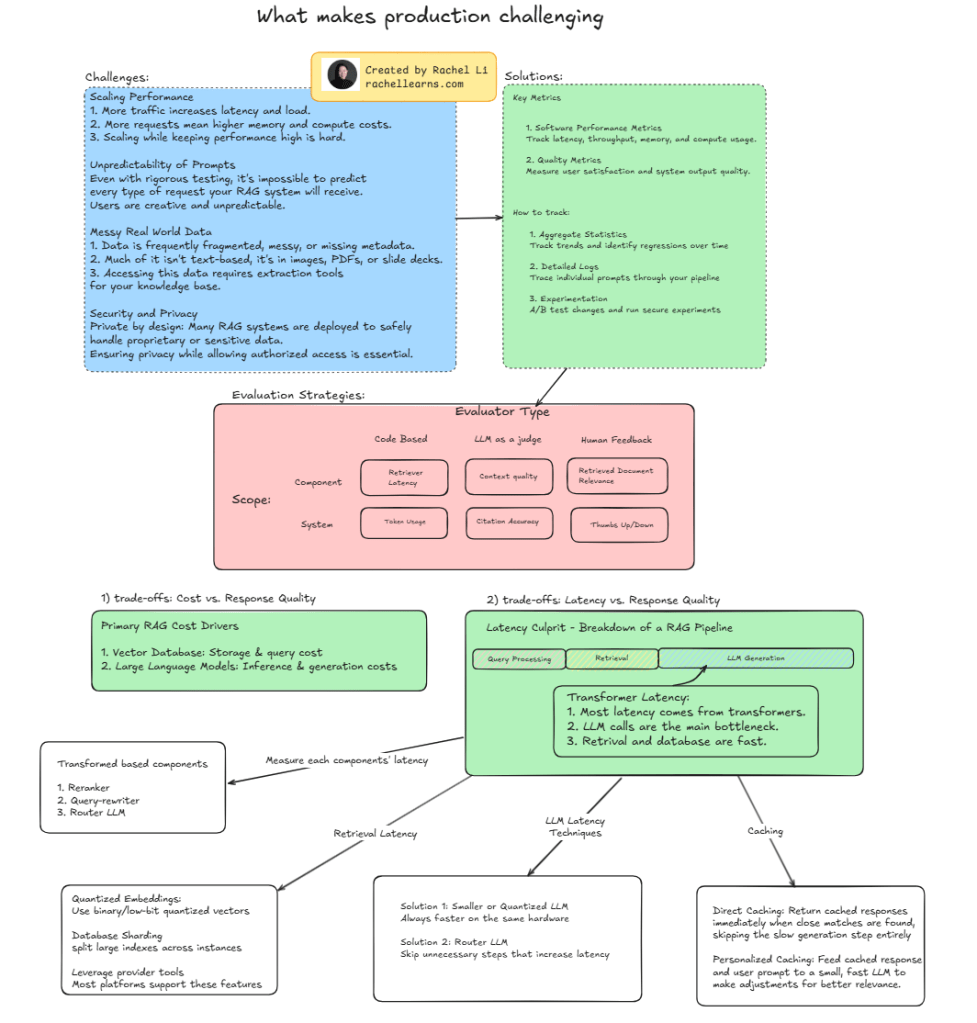
🧩 Challenges:
- Scaling efficiently while managing latency & compute cost
- Unpredictable prompts from real users
- Messy, unstructured, and multimodal data
- Ensuring security & privacy in high-stakes environments
✅ Solutions:
- Track both software performance (latency, memory, throughput) and quality metrics (user satisfaction, citation accuracy)
- Use aggregate stats, detailed logs, and experimentation (A/B testing) to iterate
⚖️ Trade-offs to navigate:
- Cost vs. Quality:
Vector DBs and LLM inference aren’t cheap. Quantized embeddings and sharding help. - Latency vs. Quality:
Most latency comes from transformers.
Solutions? Smaller LLMs, router models, caching (yes—even personalized caching!).
🔍 Evaluation strategies:
Use code-based metrics, LLM-as-a-judge, and human feedback. Evaluate both component-level and system-wide performance.
📌 This visual guide breaks it all down — from cost drivers to latency bottlenecks — and offers strategies to tame complexity in production.
💡 What trade-offs have you seen in deploying LLM-based systems?
#AI #RAG #LLM #MachineLearning #LatencyOptimization #VectorSearch #LLMops #AIProduct #MLOps #AgenticWorkflow

Leave a comment